


Table of contents
- What Are Vectors and Vector Embeddings? Why Now?
- What Is Semantic Search in Large Databases?
- Retrieval Augmented Generation (RAG): Powering LLMs with Real-World Knowledge
- The Core: Hierarchical Navigable Small Worlds (HNSW)
- HNSW Parameters: Fine-Tuning Your Search
- Resources for Exploration
- Q&A Highlights
- Conclusion
Do traditional databases feel limiting for modern AI-driven use cases? Enter the world of vector databases, where meaning trumps keywords, and similarity is the name of the game. Today, we’re diving deep into this fascinating area, guided by the expertise of Debabrata Mondal, the founder of the open-source vector database, Citrus.
Debabrata, an IT undergrad from Jadavpur University, brings a wealth of experience from companies like Dashibase, Pebblely, and Rifflix. In our recent tech talk, he shared insights into Citrus, the technical underpinnings, its market relevance, and his journey in building this innovative product.
This blog post will recap the session, from the basics of vector embeddings to the complexities of the Hierarchical Navigable Small Worlds (HNSW) algorithm.
What Are Vectors and Vector Embeddings? Why Now?
At the heart of vector databases lies the concept of vector embeddings.
What are vector embeddings?
Essentially, they are lists of floating-point numbers where each number holds a semantic meaning. When you give a prompt to an LLM (Large Language Model), it converts it into an array of numbers—this array is the vector. These numbers aren’t random; they capture the essence of the data, enabling comparisons based on meaning rather than literal content.Why are they important?
Vector embeddings represent data as points in a multi-dimensional space. The distance between these points indicates the similarity between the data.Why now?
With the rise of AI and machine learning, traditional keyword searches fall short for complex, nuanced queries. Applications reliant on semantic understanding, particularly with LLMs, demand vector databases for efficiency.
What Is Semantic Search in Large Databases?
Semantic search focuses on understanding meaning, rather than simply matching keywords.
Example: Traditional search engines might fail to connect “Apple is a great company” with “The iPhone is a great product.” Semantic search, powered by vector embeddings, recognizes the contextual relationship between these sentences.
How does it work?
Debabrata showcased an example comparing:"Apple is a great company that makes really good products"
"The iPhone is a great product"
These sentences showed high cosine similarity (a measure of angle between two vectors), whereas a sentence about the fruit “apple” showed lower similarity.
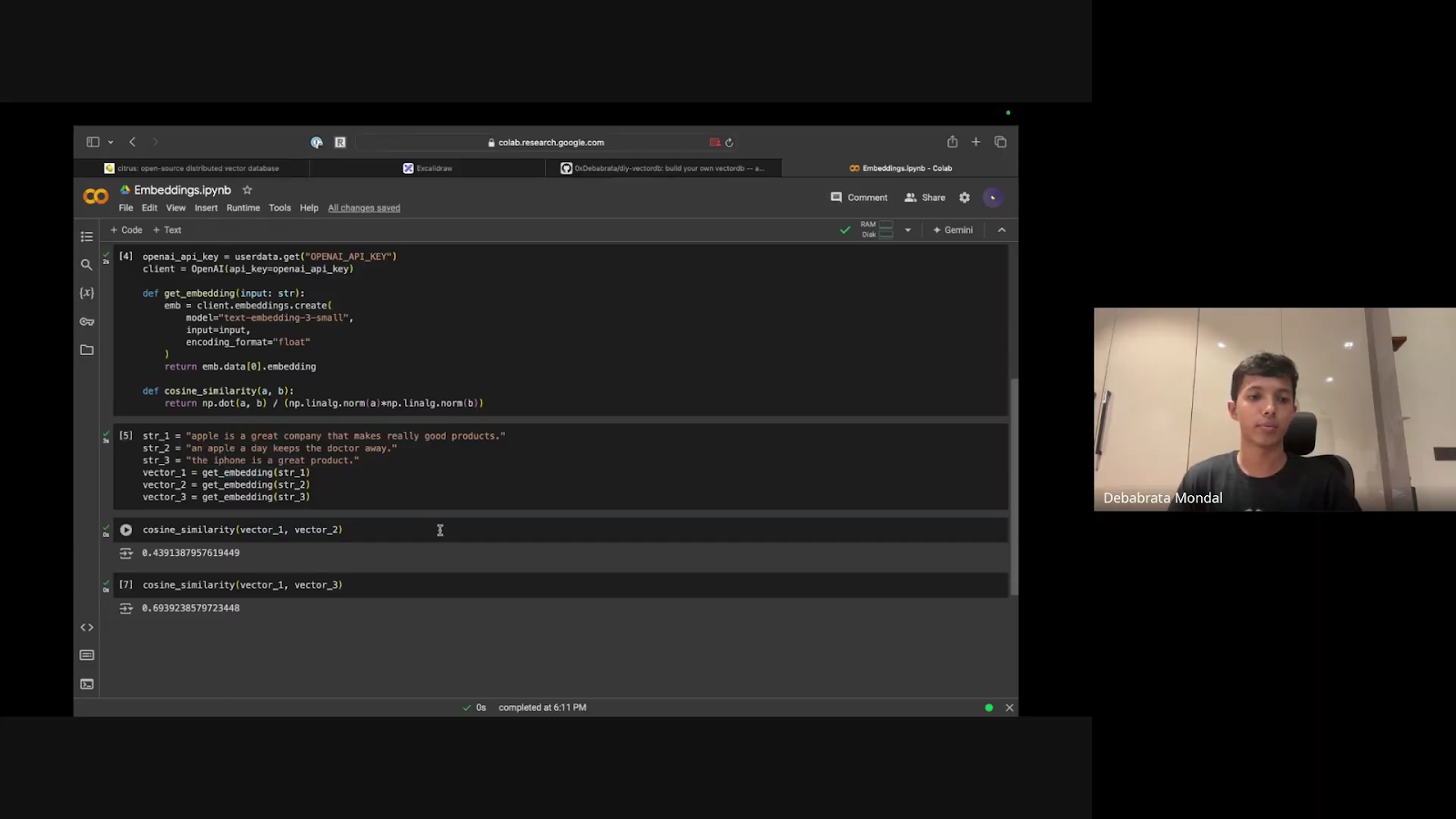
Cosine Similarity b/w 2 vectors
This capability is essential for large databases to surface contextually relevant information even without exact keyword matches.
Retrieval Augmented Generation (RAG): Powering LLMs with Real-World Knowledge
A key application for vector databases is Retrieval Augmented Generation (RAG).
How does RAG work?
Retrieve relevant information from a knowledge base using a vector database.
Pass this context to an LLM alongside the query.
The LLM generates informed and accurate responses.
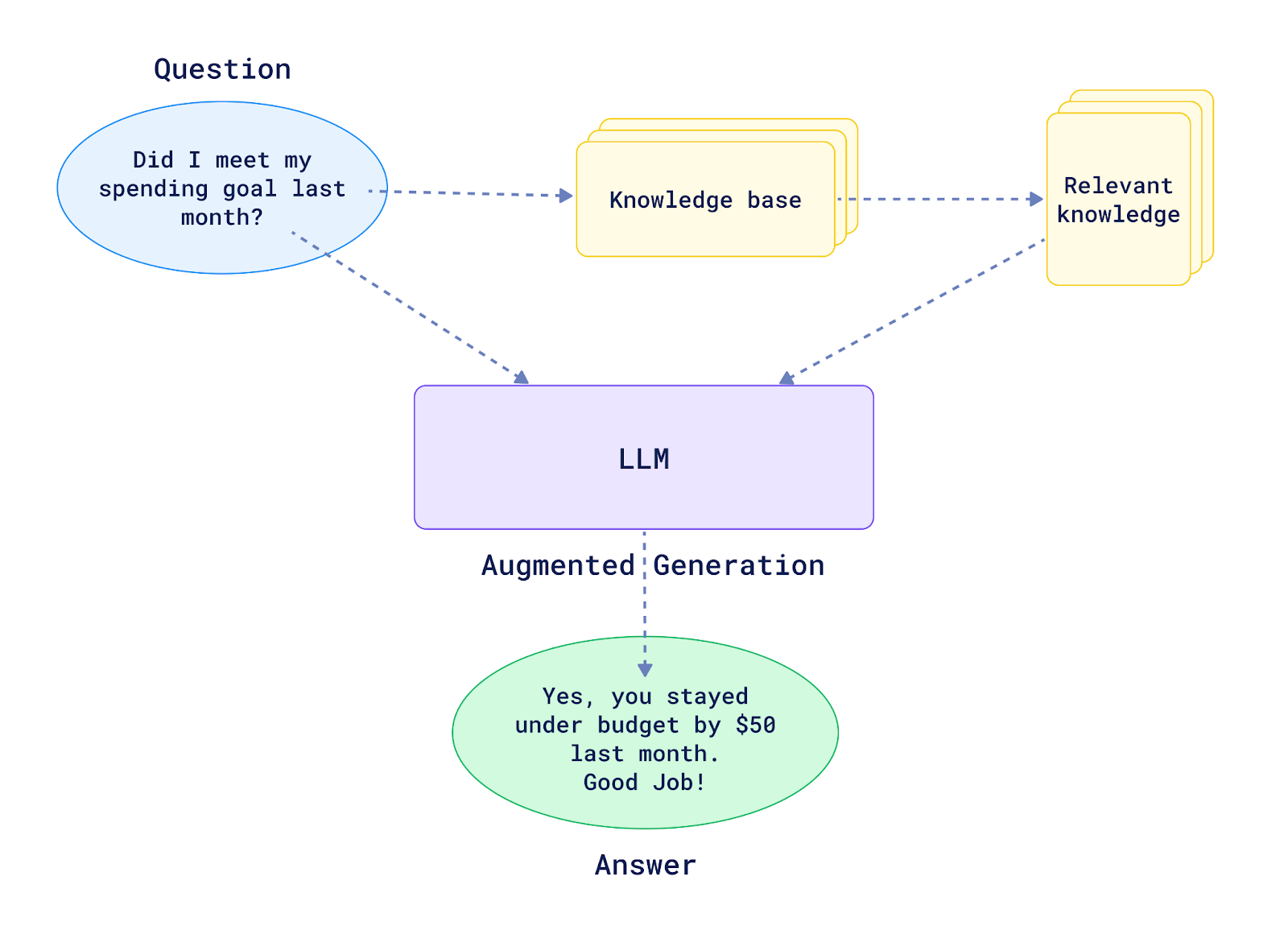
Source : qdrant.tech/articles/what-is-rag-in-ai
Without vector databases, searching large knowledge bases for semantically relevant information would be highly inefficient.
The Core: Hierarchical Navigable Small Worlds (HNSW)
When handling millions or billions of entries, comparing a query vector to every other vector is infeasible. This is where vector indices come in, enabling fast approximate nearest neighbor (ANN) searches.
Citrus leverages the HNSW algorithm for this purpose.
What Is HNSW?
HNSW is a graph-based ANN search algorithm with two core components:
Probability Skip List:
A type of linked list with multiple layers that allow faster traversal by skipping elements.
Lower layers are dense, while upper layers are sparse.

Navigable Small Worlds:
Represents vector embeddings as a proximity graph, where connections represent similarity.
Uses a greedy algorithm to navigate the graph. Starting from an entry point, it moves to the nearest neighbor until it finds the closest vector to the query.
Incorporates long-range and short-range connections for efficiency.
Hierarchical Structure
HNSW adds layers of navigable small worlds:
Top layers are sparse, enabling long jumps across the dataset.
Bottom layers are dense, allowing finer searches.
This hierarchical structure ensures quick zooming into the relevant data, making it ideal for large datasets.

HNSW Parameters: Fine-Tuning Your Search
The performance of HNSW can be fine-tuned using the following parameters:
Space: Distance metric for comparing vectors (e.g., cosine similarity).
Dimensions: Number of dimensions in vector embeddings.
k (Key/Top-k): Number of nearest neighbors to return.
ef (Enter Factor): Candidate list size during search.
ef_construction: Similar to ef, but used during the indexing phase.
M: Maximum number of connections per vector.
Adjusting these parameters helps achieve the right balance between speed and accuracy for specific datasets.
Resources for Exploration
Debabrata shared several repositories for those eager to dive deeper. You can start with his DIY - Vector DB repository and then explore the other ones.
Citrus GitHub Repo: Explore the open-source Citrus codebase, suggest features, and contribute.
FAISS GitHub Repo: Check out Facebook AI’s FAISS repository for implementing vector indices.
Hnswlib - fast approximate nearest neighbor search: Check out HNSW official repository (Header-only C++/python library for fast approximate nearest neighbors).
Q&A Highlights
Question: How big are the databases when converting sentences into vectors?
Answer: Embedding size is fixed, based on the number of dimensions (e.g., OpenAI’s embeddings have 1536 dimensions). Multiply this by 4 bytes (size of a floating-point number) for storage estimation.
Question: Can different vector sizes exist in the same index?
Answer: While possible with tricks, it’s not recommended. Create separate indices for different embedding sizes.
Question: Do vector DBs support table joins?
Answer: Vector databases complement traditional databases. Use vector DBs for semantic search and traditional DBs for business logic.
Question: Why SQLite over Postgres?**
Answer**: SQLite is lightweight and ideal for demos. It doesn’t require managing connections and creates a portable file. Citrus supports both SQLite and Postgres.
Conclusion
Vector databases like Citrus are revolutionizing information retrieval with their semantic capabilities. Their use of the HNSW algorithm, open-source nature, and adaptability make them indispensable for powering modern AI applications like RAG.
Want to dive deeper? Check out the full talk on TechKareer’s YouTube channel and explore Citrus to be part of this transformative journey!